La Facultad de Ciencias, ofrece el programa de maestría y doctorado con énfasis en Inteligencia Artificial, el cual se enmarca en el programa de posgrado institucional Maestría y Doctorado en Ciencias e Ingeniería (MYDCI). El MYDCI se encuentra reconocido ante el sistema nacional de posgrado (SNP) del CONAHCYT cuyos lineamientos aprobados por la Junta de Gobierno del CONAHCYT, organizan los programas reconocidos por la Secretaría de Educación Pública (SEP), a partir de la naturaleza pública o privada de la institución en que se impartan, y de la orientación del programa de posgrado a la investigación o a la profesionalización de las personas, con el objetivo de asignar becas para estudios de posgrado.
El énfasis en Inteligencia Artificial tiene como objetivo particular formar investigadores del más alto nivel académico en esta área de estudio, capaces de realizar investigación original, tanto teórica como aplicada, de manera independiente o colaborativa, para el desarrollo de la ciencia y la innovación tecnológica en el país. Con el fin de brindar conocimientos sólidos en esta área de estudio, los cursos y actividades formativas del programa se orientan a fortalecer competencias básicas requeridas por todo profesional en Inteligencia Artificial, así como competencias que atiendan alguna área particular de especialización (línea de énfasis) que el estudiante seleccione; tal como se describe en la sección mapa curricular.
Convocatoria
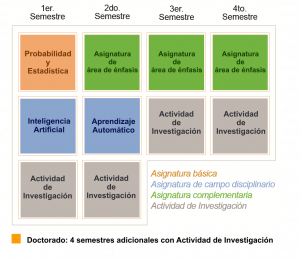
Mapa curricular maestría y doctorado
| Asignaturas de área de énfasis |
| Algoritmos genéticos en paralelo |
| Algoritmos para bioinformática |
| Aprendizaje profundo |
| Big data |
| Computación en la nube |
| Descubrimiento de conocimiento y minería de datos |
| Internet de las cosas: conectividad y protocolos |
| Introducción a los sistemas basados en agentes |
| Modelos inteligentes de aprendizaje |
| Procesamiento de imágenes digitales: algoritmos y hardware |
| Procesamiento digital de señales |
| Reconocimiento de patrones |
| Recuperación de información |
| Robótica |
Líneas de énfasis
| LÍNEAS DE ÉNFASIS | PROFESORES | MATERIAS |
| Ciencia de Datos y Cómputo Científico | Dr. Everardo Gutiérrez López Dr. Luis M. Pellegrin Zazueta Dr. Omar Álvarez Xochihua Dr. José Ángel González Fraga Dra. Selene Solorza Calderón |
Aprendizaje Automático (Ob)
|
| Tecnologías del Lenguaje |
Dr. Luis M. Pellegrin Zazueta
| Aprendizaje Automático (Ob) Minería de Datos (Op) Aprendizaje Profundo (Op) Big Data (Op) |
| Visión por Computadora |
Dr. Luis M. Pellegrin Zazueta
| Visión Artificial (Op), Procesamiento Digital de Imágenes (Op) Aprendizaje Profundo (Op) |
| Aprendizaje Computacional y Reconocimiento de Patrones |
Dr. Everardo Gutiérrez López
| Reconocimiento de Patrones (Op) Tratamiento de la Información (Op) Aprendizaje Automático (Ob) Aprendizaje Profundo (Op) Análisis Multiresolución Wavelet (Op) |
| Cómputo Evolutivo |
Dr. Everardo Gutiérrez López
| Algoritmos Genéticos (Op) Algoritmos Bioinspirados (Op) |
| Robótica |
Dr. Luis M. Pellegrin Zazueta
| Robótica (Op) Visión Robótica (Op) Control y Planeación (Op) |
| Tecnologías Web y Sistemas Multiagentes |
Dr. Omar Álvarez Xochihua
| Big Data (Op) Sistemas Multiagentes (Op) Cloud Computing (op) IoT (op), Sistemas Distribuidos (op) |
| Ambientes Inteligentes |
Dra. María Victoria Meza Kubo
| Cómputo ubicuo (Op) Interfaz humano-computadora (Op) Diseño de interacción (op) |
Algunos proyectos de Investigación
Modelo predictivo de situaciones de CyberBullyng en redes sociales
(Responsable: Dr. Omar Álvarez Xochihua)
El cyberbullying tiene los mismos efectos que el bullying tradicional, daña la confianza y la autoestima de la víctima, provocando ansiedad, frustración e ideas suicidas. Ante esta variación, los programas de atención de esta problemática y los desarrollos tecnológicos tienen que adaptarse para detectar a tiempo situaciones de cyberbullying generadas mediante el uso de tecnologías de información y comunicación actuales, como las redes sociales, celulares e Internet; con el objetivo de actuar en contra de este tipo de agresión y proveer atención inmediata a la víctima.
En la presente investigación se tiene como objetivo principal el crear un modelo predictivo, robusto y escalable, que permita predecir escenarios de cyberbullying en espacios virtuales en lenguaje español previa su materialización, potenciales a trasladarse a entornos físicos. El modelo se basa en el análisis de conversaciones realizadas en grupos de redes sociales, mediante el uso de técnicas y algoritmos de procesamiento de lenguaje natural, construido y validado con datos multimedia que estos mismos entornos generan. Así como, diseñar los algoritmos que permitan implementar y manipular dicho modelo como una aplicación de usuario final en ambientes de redes sociales de frecuente uso, con el objetivo último de enviar alertas de situaciones de bullying entre los grupos de estudiantes y autoridades educativas que permita intervenir de forma temprana para contrarrestar los efectos de este fenómeno.
Al momento, el grupo de investigadores participantes cuenta con trabajo realizado al respecto y un estudiante doctoral con el tema “Modelo Predictivo de Escenarios de Cyberbullying en Espacios Virtuales de Habla Hispana”. Se cuenta ya con un banco de datos inicial, obtenido con estudiantes de nivel medio superior y superior provenientes de tres instituciones educativas, dos públicas y una privada. Este banco de datos cuenta con más de 400 conversaciones, que representan más de 3000 enunciados que incluyen texto, emoticonos e imágenes. De igual forma, se ha realizado un proceso de etiquetado por especialistas en el área que ha permitido generar un primer corpus para la elaboración del modelo inicial.
Arquitectura núcleo para la cooperación entre tutores inteligentes
(Responsable: Dr. Omar Álvarez Xochihua)
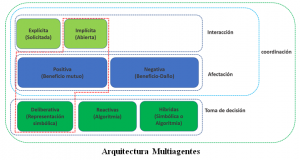
Esta investigación atiende el ámbito de tecnología educativa, mediante el diseño, implementación y evaluación de una arquitectura de software que permite la comunicación entre tutores inteligentes (agentes pedagógicos), permitiendo homogeneizar el modelo del estudiante para ser compartido entre tutore inteligentes de diferentes dominios. Los sistemas de tutoría inteligente (ITS, por sus siglas en inglés), son asesores virtuales basados en software, que surgen como una opción para incrementar el desempeño académico de los estudiantes al brindarles asesoría personalizada; mediante conocimiento previamente obtenido de asesores humanos.
Para el modelado del conocimiento se utilizaron herramientas de la web semántica; se tomó la decisión de utilizar técnicas de modelado de conocimiento mediante semántica ontológica. El diseño de la arquitectura integral de tutores inteligentes se fundamentó en un metamodelo basado en la Arquitectura Dirigida por Modelos, separando los flujos funcionales (servicios) de las tecnologías que los implementan. Al mismo tiempo, se sustenta una arquitectura de comunicación multiagentes deliberativa, mediante una relación positiva e interacción implícita. El protocolo de comunicación entre tutores implementado se realiza utilizando la especificación xAPI y un repositorio LRS, debido a las bondades que esta ofrece para que sistemas muy diferentes puedan comunicarse entre sí mientras interactúan con diferentes tecnologías y contenidos.
Detección de cáncer de mama en mamografías, empleando técnicas de aprendizaje automático
(Responsable: Dr. Jóse Ángel González Fraga)
Típicamente los radiólogos utilizan sistemas de detección asistida por computadora (CAD) como segundo intérprete para la detección del cáncer de mama en las mamografías. Sin embargo, en muchos casos el sistema puede determinar falsas predicciones, por lo que el radiólogo debe revisar. En este trabajo se exploran diferentes enfoques de aprendizaje automático para la detección y clasificación de anomalías mamarias utilizando técnicas de procesamiento de imágenes.
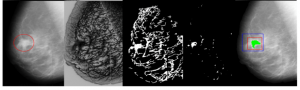
Figura tomada de: Diaz-Escobar, J. and Kober, V., 2019, September.
Classification of breast abnormalities in digital mammography using phase-based features.
In Applications of Digital Image Processing XLII (Vol. 11137, p. 1113724).
International Society for Optics and Photonics.
Desarrollo de algoritmos para el problema de Visual SLAM empleando sensores tipo Kinect
(Responsable: Dr. Jóse Ángel González Fraga)
El objetivo de un sistema SLAM es determinar la posición de un robot, un vehículo o una cámara en movimiento en un entorno y, al mismo tiempo, construir una representación cartográfica del espacio de trabajo explorado. Las aplicaciones pueden ser para sistemas de navegación de vehículos autónomos, rescate en entornos de alto riesgo, exploración en entornos hostiles, aplicaciones de realidad aumentada, sistemas de vigilancia, aplicaciones médicas, etc. En este proyecto se desarrollan algoritmos que permitan optimizar las diferentes etapas del problema, iniciando desde la captura y procesamiento de los datos 3D, hasta la generación del mapa 3D.

Desarrollo de algoritmos para el problema de seguimiento de objetos 3D
(Responsable: Dr. Jóse Ángel González Fraga)
El seguimiento de objetos (tracking) en problemas de visión por computadora es un área de investigación desafiante debido a muchos factores, como cambios en la apariencia del objeto (escala y deformación), cambios de iluminación, oclusiones y movimientos rápidos tanto del objeto como de la cámara. Para mejorar el desempeño de los algoritmos del seguimiento, en los últimos años se han incorporado elementos, como la información de profundidad que puede proporcionar una cámara RGB-D (como el sensor Kinect). El seguimiento de objetos y la estimación de movimiento son algunos de los temas que pueden atacar utilizando sensores RGB-D. Con la información de profundidad, los cambios de escala y los problemas de oclusión se pueden manejar principalmente.
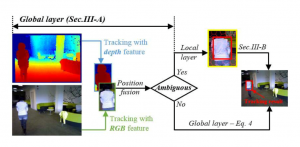
Figura tomada de: Xiao, J., Stolkin, R., Gao, Y. and Leonardis, A., 2017.
Robust fusion of color and depth data for RGB-D target tracking using adaptive
range-invariant depth models and spatio-temporal consistency constraints.
IEEE transactions on cybernetics, 48(8), pp.2485-2499.
Desarrollo de aplicaciones de bajo costo para el estudio de las bases
biológicas de la conducta en el pez cebra
(Responsable: Dr. Jóse Ángel González Fraga)
El pez cebra es un poderoso modelo para el estudio de las bases biológicas de la conducta, a la fecha numerosas herramientas de acceso libre permiten realizar pruebas conductuales. El objetivo de este proyecto es utilizar plataformas como Matlab, Labview y Arduino para desarrollar scripts de acceso libre que puedan reemplazar a los costosos dispositvos y software comerciales. Se trabaja en un equipo interdisciplinario con expertos en el área de biología.

González-Fraga, Jose, Victor Dipp-Alvarez, and Ulises Bardullas.
“Quantification of Spontaneous Tail Movement in Zebrafish Embryos
Using a Novel Open-Source MATLAB Application.”
Zebrafish 16, no. 2 (2019): 214-216.
Hacia la Identificación Automática del Borrego Cimarrón (Ovis canadensis)
y Otras Especies para el Manejo y Conservación de Vida Silvestre
(Responsable: Dr. Luis M. Pellegrin Zazueta)
La identificación de animales en su hábitat natural es una tarea de suma importancia para el control de mortandad de diversas especies, mejorando su conservación en ambientes naturales. Para llevar a cabo un monitoreo de la biodiversidad de la vida silvestres se han empleado cámaras y videocámaras digitales colocadas estratégicamente. Un experto en la materia utiliza las imágenes proporcionadas por dichos dispositivos y realiza de manera manual tres diferentes tareas: reconocimiento, que consiste en determinar la presencia de un animal en la imagen; clasificación, en donde se categoriza al animal en especies; y la identificación individualizada del animal en su misma especie. En el presente proyecto se propone un marco de trabajo para atacar estas diferentes tareas mediante métodos computacionales. En particular la tarea de identificación en computación es definida como clasificación de grano fino, siendo esta tarea de gran interés para la comunidad científica. El marco de trabajo está compuesto por métodos basados en el paradigma de aprendizaje profundo. Aprendizaje profundo ha introducidos en los últimos años importantes contribuciones que han sido parteaguas en diferentes tareas relacionadas con imágenes. Los resultados esperados impactarán en producción científica, introducción de herramientas de importancia para la biología de la conservación, colaboraciones interdisciplinarias (biología y computación), y colaboraciones interinstitucionales.

Descripción Automática de Imágenes a través de Métodos
basados en Aprendizaje de Representaciones
(Responsable: Dr. Luis M. Pellegrin Zazueta)
Los avances tecnológicos han convertido a la Web en un gran corpus que contiene muchos tipos de recursos de información (documentos, imágenes, video y audio). En esta era de “Big Data”, el aprendizaje supervisado se ha aplicado ampliamente para organizar y descubrir automáticamente nuevo conocimiento en una amplia variedad de tareas. Recientemente, los enfoques basados en el aprendizaje profundo han demostrado ser efectivos para abordar una serie de diferentes tareas visuales, como la clasificación de imágenes, el reconocimiento de objetos, la segmentación, etc. A pesar de la efectividad comprobada de los modelos de aprendizaje profundo, la ventaja real de tales enfoques es posible cuando hay grandes cantidades de ejemplos de entrenamiento disponibles. El problema es que obtener tales ejemplos etiquetados es un trabajo de gran costo en esfuerzo y tiempo, y en algunos casos solo es posible si los expertos en el dominio realizan las anotaciones manualmente. Motivados por este escenario, en este proyecto, proponemos el uso de representaciones aprendidas por arquitecturas de aprendizaje profundo para el descubrimiento de la relación semántica entre los elementos en documentos extraídos de la Web para la descripción automática de imágenes en un escenario no supervisado. Tomando este escenario del problema, este proyecto está dirigido a la investigación de dos aspectos que no se han estudiado ampliamente: (1) un marco para la generación automática de conjuntos de datos a través de la aplicación de técnicas enfocadas en el texto mediante el uso del aprendizaje de representaciones ; y (2) métodos novedosos de anotación de imagen no supervisada basados en el descubrimiento de asociaciones de interés entre representaciones de texto e imagen obtenidas mediante aprendizaje de transferencia y representaciones distributivas.
![]()
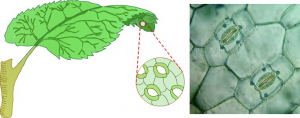
Identificación y conteo automático de estomas
(Responsable: Dr. Luis M. Pellegrin Zazueta)
El análisis de imágenes microscópicas en biología no es una tarea sencilla. Conlleva un tiempo laborioso en el cual se busca identificar características ya sea para categorizar o contabilizar, muchas veces de manera manual o utilizando un software especializado que apoya a expertos. Un caso es el estudio de estomas, que son pequeños poros en las superficies de las hojas, tallos, partes de flores y frutos de angiospermas. Están formados por un par de células epidérmicas especializadas que se encuentran en la superficie en la mayoría plantas superiores. El estudio microscópico de las epidermis de las hojas ayuda a los investigadores a entender mejor su comportamiento general y salud de las plantas. El presente proyecto tiene como objetivo la generación de método especializados de conteo y clasificación automática de estomas, mediante un enfoque de aprendizaje profundo.
Modelos de inteligencia artificial para la integración de datos en apoyo
a la detección temprana de cáncer de mama
(Responsable: Dr. Everardo Gutiérrez López)
Las tasas de incidencia y mortalidad del cáncer de mama en la población mundial evidencian la relevancia de esta enfermedad, de la cual los organismos internacionales concuerdan que el elemento clave para su combate es la detección temprana. La problemática es compleja, tanto desde el punto de vista computacional como médico, debido a la diversidad de las fuentes de datos (imágenes, factores de riesgo, genéticos, etc.), la variabilidad en el impacto de los diferentes factores involucrados, el acceso a la información, entre otros elementos. Se propone la creación de modelos de inteligencia artificial para la integración de datos en apoyo a un adecuado seguimiento durante el proceso de detección temprana de cáncer de mama.

Foto tomada de Twitter | The Daily Targum
Plataforma de aplicaciones de cómputo ubicuo para asistir
al adulto mayor con deterioro cognitivo.
(Responsables: Dr. Alberto Leopoldo Morán y Solares, Dra. María Victoria Meza Kubo)
Este proyecto tiene el objetivo de proveer tecnologías de asistencia para adultos mayores que les permita tener una vejez con mayor calidad de vida, enfocándonos en el diseño de tecnologías de cómputo ubicuo para atender la salud cognitiva del adulto mayor con deterioro cognoscitivo leve y sus cuidadores que incluyan estrategias para la realización de actividades para la estimulación cognitiva.

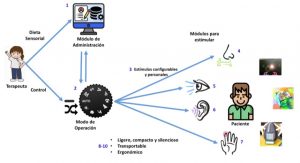
Interfaces cerebrales (BCI) para aplicaciones de estimulación cognoscitiva para pacientes
con enfermedades cerebrovasculares (ECV)
(Responsables: Dr. Alberto Leopoldo Morán y Solares, Dra. María Victoria Meza Kubo)
Desarrollar aplicaciones BCI que promuevan, a través de la estimulación cognitiva la recuperación de las funciones cognoscitivas de pacientes con movilidad restringida que han sufrido una ECV.

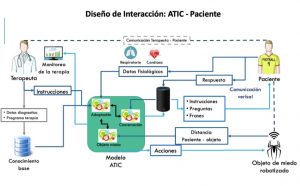
Asistente Terapéutico Inteligente Conversacional para guiar un
tratamiento de fobias a animales pequeños
(Responsables: Dr. Alberto Leopoldo Morán y Solares, Dra. María Victoria Meza Kubo)
En este proyecto se propone desarrollar un modelo computacional para un Asistente Terapeuta Inteligente Conversacional (ATIC), mediante el uso de cómputo consciente del contexto y aprendizaje automático, que sea capaz de guiar el progreso de una TE de fobias a animales pequeños, interactuando de manera verbal con el paciente.
Espacios personales de estimulación multisensorial como apoyo para la terapia
de pacientes con discapacidad cognitiva
(Responsables: Dr. Alberto Leopoldo Morán y Solares, Dra. María Victoria Meza Kubo)
Proponer y evaluar un modelo para el diseño de Espacios Personales de Estimulación Multisensorial (PS4MS), que sean útiles para apoyar la terapia de pacientes con discapacidad cognitiva, que sean eficientes, y generen experiencias de usuario satisfactorias.
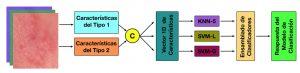
Extracción de características de textura para imágenes digitales
(Responsable: Dra. Selene Solorza Calderón )
En las áreas de Procesamiento de Imágenes, Inteligencia Artificial y Visión por Computadora la clasificación de patrones o la reconstrucción de objetos son etapas críticas para el apropiado funcionamiento de los sistemas o prototipos. Frecuentemente, la extracción de los descriptores de objetos con texturas y transformaciones geométricas juegan un role dominante en la clasificación y en la reconstrucción. En las últimas décadas, las técnicas de textura han sido muy utilizadas en la clasificación de imágenes digitales con geometrías amorfas. Dichas técnicas han demostrado ser una herramienta muy útil para procesar imágenes microscópicas, satelitales, de ultrasonido y de tomografía axial computarizada. El presente proyecto tiene como objetivo desarrollar metodologías para el reconocimiento de patrones en imágenes digitales mediante las técnicas de texturas.
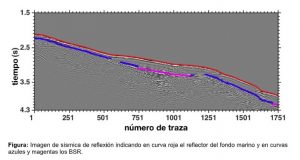
Extracción de características en imágenes sísmicas
(Responsable: Dra. Selene Solorza Calderón )
El procesamiento digital de señales mediante el uso de las transformadas integrales tiene un amplio rango de aplicaciones encaminadas a la identificación de patrones en diferentes áreas. Una de las tareas del reconocimiento de patrones se enfoca en la extracción de características que permitan representar y describir la señal como una entidad única para poder distinguirla de otras señales y a su vez identificarla como integrante de alguna clase. Por ejemplo, desde 2018 hemos estado desarrollando el modelo de reconocimiento automatizado del BSR (reflector simulador del fondo marino) en imágenes de sísmica reflexión. El BSR es uno de los marcadores de la presencia de hidratos de gas en las imágenes marinas de sísmica de reflexión. En la actualidad, uno de los campos activos de investigación es el estudio del papel de los hidratos de gas y el gas libre en la temperatura del océano, el nivel del mar y los cambios climáticos. Por lo tanto, es crucial estimar las concentraciones de metano en las zonas de hidratos/gas libre. Además, investigaciones recientes muestran que los hidratos de metano podrían convertirse en nuevos recursos energéticos para los países con reservas de hidratos/gas libre. Sus aplicaciones industriales han aumentado, se está entendiendo su papel en la naturaleza, se están desarrollando métodos para extraer de manera segura los gases naturales almacenados en zonas de hidratos/gas libre y se están desarrollando tecnologías ecológicas. Por lo general, la localización del BSR la realiza manualmente un intérprete capacitado, por lo tanto, contar con un modelo automatizado especializado en localizar el BSR es una herramienta útil. El presente proyecto tiene como objetivo desarrollar metodologías para la extracción de reflectores y su localización en imágenes sísmicas.